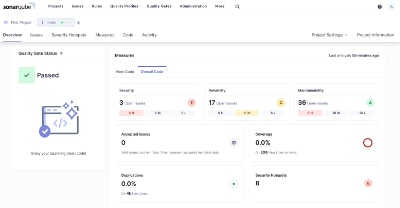
Whether you write code professionally or just as a hobby, static code analysis is an important tool for any developer to find bugs, security vulnerabilities, and opportunities to improve the quality of your code. The most popular tool is called Sonarqube which offers a free open-source community edition that can be installed locally and supports most of the popular languages. While it does not have...
Read More
Software packages on Linux or Unix are typically distributed and installed from repositories using a special utility called a package manager. This utility simplifies the installation of a package and makes sure all the dependencies of the software are also met and installed. In addition, the package manager makes it easy to install updates or remove the software package. While macOS is a descendant...
Read More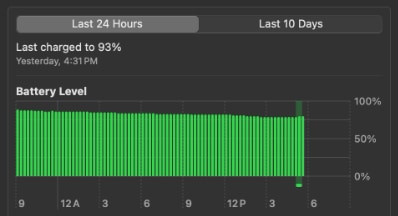
It's pretty well known that battery capacity degrades over time, but did you know you can control how fast the battery degrades based on how you charge it? The lithium-ion battery found in your MacBook is built with the latest technology and macOS (Big Sur and newer) includes special "Optimized Battery Charging" algorithms to extend the battery life. However, these special software optimizations work...
Read More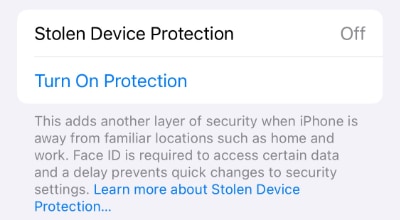
Stolen Device Protection is a new capability first appearing in iOS 17.3 that provides an additional layer of protection in the event your iPhone is stolen and the thief forces you to unlock your phone or tell them your passcode. When enabled, sensitive operations such as changing the device passcode, accessing your stored passwords or credit cards, and changes to your Apple ID require additional biometric...
Read More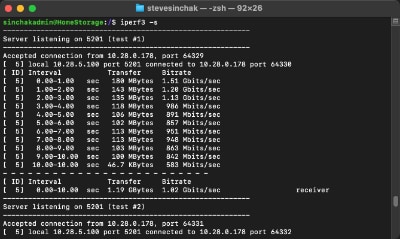
I recently upgraded my home network from gigabit to 10G so I could take advantage of faster transfers between my Synology NAS, Proxmox server, and workstations. But while editing family video clips stored on my NAS, something did not feel right. Every device was connected at 10GbE, but file copy speeds were slower than expected. This made me wonder, are there bottlenecks in my network?
Read MoreAre you looking for a large file to test disk file transfers or your internal network speed? Instead of downloading a massive test file and wasting your Internet bandwidth, simply generate one with a simple command right on your Mac.
Read More
Did you know there is a comprehensive screenshot and recording capability built right into modern versions of macOS? That's right, say goodbye to third-party utilities, macOS has you covered. Activated using special keyboard shortcuts (or via terminal), more than a dozen options are available to help you take every type of screenshot you will ever need along with customizations to include a timer delay...
Read More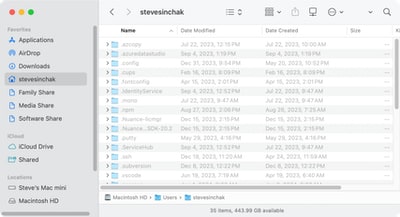
There are many situations when you need to view hidden files on Mac. Especially if you are doing software development as there are a lot of files that start with a . (dot), such as the .gitignore file, as any file that starts with a dot is hidden automatically. This was especially annoying for me when I realized my Eleventy configuration file .eleventy.js was missing because Finder does not...

I recently helped migrate an Office 365 contact list over to the Apple Contacts ecosystem. While there are a lot of off-the-shelf products you can buy, I approached this as a project to build a free CSV to vCard (VCF) conversion tool (built right into this page) that would help anyone else in a similar situation without having to buy or install anything.
Read More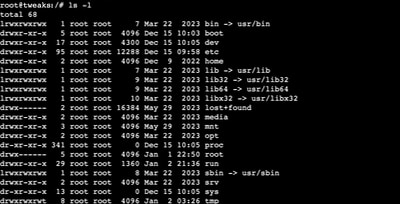
The file system structure on most Linux distributions is loosely based on something called the Filesystem Hierarchy Standard which guides the usage of the various root directories. This article was created to help beginner Linux users with a "cheat sheet" of the most common Linux directories along with a deeper detailed explanation...
Read More